

Trojans in your source code
- Coen Goedegebure
- Nov 15, 2021
- 4 min read

As part of my work I frequently perform source code reviews for security issues. Looking for vulnerabilities in the logic of the source code is not easy, but when the encoding of that code is attacked, things get unreal pretty fast. Especially when you realise how often code is copy-pasted from sites like StackOverflow.
This article describes the dangers of hidden Unicode control characters and how they can make your source code appear differently than it is executed.
The vulnerability
Consider the following piece of Javascript:
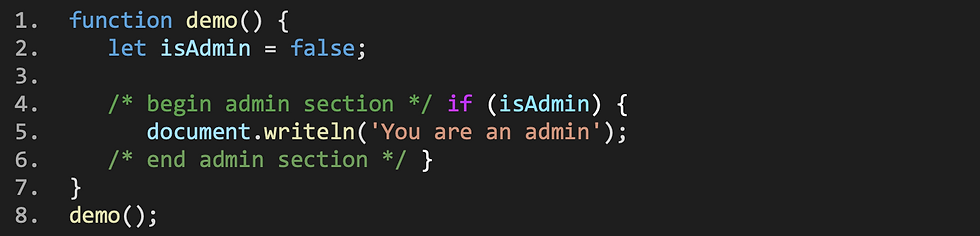
This code contains a simple "demo"-function that starts by setting the "isAdmin" variable to "false" in line 2. Line 4 starts with a comment and checks whether "isAdmin" is set to "true" in which case the message "You are an admin" would be printed in line 5. Logically, this message will never be printed since "isAdmin" is explicitly set to "false". However, when executing this script, the following output is generated:
You are an adminHow does this work?
Using Unicode control characters we can reorder the tokens of the source code. By doing this, the way the source code is rendered to screen no longer matches the actual logic of the source code itself.
In other words, by carefully placing these control characters, we can visually reorder the source code so that it is displayed differently than how it is processed by the compiler or interpreter.
Modifying the code
The table below lists the abbreviations of the special Unicode control characters that are used to create the examples in this chapter.
Abbreviation | Unicode | Name | Description |
|---|---|---|---|
RLO | U+202E | Right-to-Left Override | Treat following text as right-to-left |
LRI | U+2066 | Left-to-Right Isolate | Treat following text as left-to-right without affecting adjacent text |
PDI | U+2069 | Pop Directional Isolate | Terminate the nearest LRI or RLI |
The example mentioned at the beginning of the article, works by making a comment appear as if it were code. Let's again take a look at how the IDE displays the Javascript code:
Now compare it to the way the code is handled by the Javascript interpreter. In the figure below the Unicode control characters are made visible:

As you can see, line 4 is processed as a normal comment section with some special characters in it. However, when the line is displayed on screen in the IDE, the special characters inside the comment manipulate the text so that it is rendered in a different order. This vulnerability is tracked as CVE-2021-42574. The sample code can be found here.
Impact
Adversaries can use this vulnerability, the difference between handling and rendering of these Unicode control characters, to hide malicious behaviour from human reviewers. The impact of this kind of an attack lies within the context of software supply chains; open source projects used by other applications. When a vulnerability like this slips through the code review and ends up unnoticed in an open source library, it is likely to be inherited downstream by the software using that library.
Exploits
Visually reordering the source code can be done in different ways:
Commenting-Out
This is the example explained above. Comments visually appear as executable code, which are not executed by compiler or interpreter.
Commenting-In
In this case, executable code visually appears to be a comment, but is actually executed. For example, in the python code below, the code "amount -= 70" in line 3 appears to be part of a comment section:

However, after running the script, we see it is actually executed:
Amount: 30
doneBelow is the actual code, with Unicode control characters made visible, as it would be processed by the python interpreter:

The sample code can be found here.
Early returns
This technique is a variation on the commenting-in technique. It executes a return statement that appears to be part of a comment, to exit a function early. In the python example below, the "return" command in line 3 appears to be included in the comment, but is actually executed.

Output:
first comment
doneThe figure below shows the code as it is processed by the python interpreter:

The early returns example can be found here.
Stretched strings
Another way to exploit this vulnerability, is to have pieces of string literals render as code. This could break equality checks like the one in the bash script below:

Line 2 assigns the value "user" to the ACCESS_LEVEL variable. If the ACCESS_LEVEL is not equal to "user" (line 4), the message "You are an admin" is displayed, otherwise the output is "You are a user". Since the ACCESS_LEVEL has been explicitly set to "user", we would expect the output is the latter. The output however is the following:
You are an adminThe figure below shows the source code as it is processed by the bash interpreter:

Notice the string literal in line 4 is not "user", but rather contains other characters as well. This way, given the explicit assignment in line 2, the comparison in line 4 always yields true (i.e. ACCESS_LEVEL is never equal to "user") and the message "You are an admin" is output.
The sample code for stretched strings can be found here.
Homoglyphs
A homoglyph attack exploits the fact that two characters look alike. For example, it is hard to see the difference between the Cyrillic letter "a" (U+0430) and the letter "a" from the latin alphabet. This is a similar to the IDN homograph attack in which domain names are spoofed using the same principle.
In the following Javascript snippet an extra, evil function 'demo' was created in which the letter "e" is replaced by the Cyrillic letter "e" (U+0435, marked in red).

It would be very difficult for a reviewer to visually make a distinction between the function call to the good and the evil demo function in line 8. This vulnerability is tracked as CVE-2021-42694.
Mitigation
The issues mentioned in this article can be mitigated by limiting the way the bidirectional Unicode control characters are processed. Either by making these clearly visible, or producing errors or warnings when these characters are encountered:
GUI
IDE's and other code editors should provide visual feedback for these characters. Either by making them clearly visible, or notifying the user with a warning. The figure below depicts how IntelliJ handles the visual representation of Unicode control characters for example:

The example below shows how GitHub handles the issue in comment_in.py:

Automated systems and software
Systems and software that process source code, like compilers, interpreters, build pipelines, etc. should throw exceptions or generate warnings whenever special characters are encountered.
Language specifications
Unterminated bidirectional control characters in comments and string literals should be disallowed by means of language specifications.
Reference: Paper: "Trojan Source: Invisible Vulnerabilities" by Nicholas Boucher and Ross Anderson, 2021 [link (pdf)]



Comments